Исследователи из Колумбийского университета разобрались, как слуховая кора умудряется выделять один голос среди многих других и делать его «громче».
В своей более ранней работе ученые под руководством Нимы Месгарани выяснили, что человеческий мозг избирателен в отношении звуков, которые он слышит. Когда мы прислушиваемся к кому-то на шумной вечеринке, остальные голоса в помещении сливаются в шум. Наша волновая мозговая активность изменяется, чтобы выделить звуки голоса интересующего нас собеседника и отсеять другие. В новом исследовании авторы хотели понять, как это происходит на уровне анатомии слуховой коры. Статья об этом опубликована в издании Neuron.
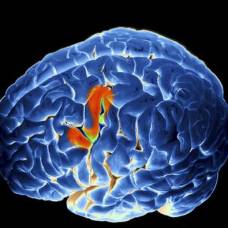
Слуховая кора — сложноорганизованная подсистема мозга. Первичная слуховая кора участвует в восприятии звуковых сигналов и передаче их во вторичную, где эти сигналы распознаются и декодируются. «Мы давно знаем, что области слуховой коры иерархически устроены, причем на каждом этапе происходит все более сложное декодирование, но мы не видели, как именно голос конкретного говорящего обрабатывается на этом пути. Чтобы понять этот процесс, нужно было напрямую регистрировать нейронную активность мозга»», — поясняет доктор Джеймс О’Салливан, ведущий автор статьи.
Первичная информация о звуке, обрабатываемая в височной доле коры больших полушарий мозга, анализируется иерархически. Вначале она попадает в поперечные височные извилины (извилины Гешля), а затем в верхнюю височную извилину. Чтобы понять, какие процессы протекают в момент распознавания голоса в этих регионах мозга, ученые сняли данные с помощью электродов.
Добровольцы, участвовавшие в эксперименте, нуждались в операции из-за эпилепсии, поэтому у авторов работы была возможность провести инвазивное обследование. Пациенты прослушивали записи разговоров людей, в то время как ученые регистрировали мозговую активность с помощью электродов, имплантированных в области извилин Гешля (HG) или верхней височной (STG).
Оказалось, у этих двух регионов есть четкое распределение ролей при интерпретации звуков. Изначально в HG попадает единый недифференцированный звук — смесь различных шумов и голосов. Там каждый компонент оказывается выделен различиями в частоте. В этом регионе ни один из голосов, одновременно декодировавшихся из общего «ковра» звуков, не был предпочтен другим. Совершенно другие данные получены из STG. Именно на этом этапе происходит выбор «ведущего голоса».
«Мы обнаружили, что голос одного говорящего или другого можно усилить путем правильного взвешивания выходного сигнала, поступающего от HG. Исходя из наших записей, вполне вероятно, что регион STG выполняет такое взвешивание», — рассказал доктор О’Салливан.
Стоит отметить, что все это происходит за 150 миллисекунд, что кажется самому человеку мгновенным. При этом STG формирует образ говорящего — слуховой аналог визуального образа, который мы создаем, представляя себе нечто, видимое глазами. Благодаря этому мы можем воспринимать речь человека как единое целое, даже если его голос периодически перекрывается более громкими звуками или реплики чередуются с ответами других людей.
По словам Месгарани, эта работа пролила свет на критично важные данные, которые необходимы для развития технологий речи и слуха. Они могут помочь при дальнейших разработках в области слуховых аппаратов и интерфейсов мозг-компьютер.